23 Jun 2013
I'm a huge proponent of test driven development and have been feeling
sort of guilty about a gem that I wrote which does not encourage
testing whatsoever. The gem, ClassyEnum,
provides class-based enumerator functionality on top of Active Record. This blog post is not so much
about the gem itself, so If you're interested in reading more about it,
the README has some good examples.
Historically, ClassyEnum has had a built-in generator to
quickly create classes that represent enum members. While this has served me
well, it has never generated any spec files along with these classes.
I always end up either creating them manually, or just forgoing tests
altogether. Neither option was great, so I wanted to see what it would
take to create spec files automatically, similar to how Rails can
generate model specs when using the model or scaffold generators.
When ClassyEnum is installed in your Rails project, you can run the generator like so:
$ rails g classy_enum Priority low medium high
create app/enums
create app/enums/priority.rb
Which produces the following file:
app/enums/priority.rb
class Priority < ClassyEnum::Base
end
class Priority::Low < Priority
end
class Priority::Medium < Priority
end
class Priority::High < Priority
end
Each Priority subclass represents an enum member, and behaves like a
true Ruby class. This boilerplate code starts out innocent enough,
as most code does, but over time, I find myself adding logic
and properties to these classes. Depending on how lazy I am,
sometimes I test it, sometimes I don't.
Exploring the Unspectacular Generator
The code for the "main" generator in ClassyEnum is fairly straightforward. It
has a description, takes a few arguments, and copies a dynamically generated
file into app/enums, creating the directory if it does not exist.
lib/generators/classyenum/classyenum_generator.rb
class ClassyEnumGenerator < Rails::Generators::NamedBase
desc "Generate a ClassyEnum definition in app/enums/"
argument :name, :type => :string, :required => true, :banner => 'EnumName'
argument :values, :type => :array, :default => [], :banner => 'value1 value2 value3 etc...'
source_root File.expand_path("../templates", __FILE__)
def copy_files # :nodoc:
empty_directory 'app/enums'
template "enum.rb", "app/enums/#{file_name}.rb"
end
end
I would recommend the Rails Generator Guide
if you aren't familiar with the syntax. You may also want to read the
Thor documentation
which is the foundation for the Rails generator DSL.
Making the Generator Spectacular
I had four main requirements for my generator's new behavior:
- It must automatically create specs in spec/enums when the generator
is run.
- The specs it creates must work out of the box (even if they are
pending).
- It cannot break existing behavior.
- It must be future proof by not relying on or hacking internal Rails or Rspec code
After digging around on Stack Overflow and reading the Rails Guide,
I discovered that Rails exposes a hook_for
method. When passed the :test_framework argument,
the main generator can automatically figure out which test framework your application is
using, and based on naming conventions, which spec generator to load.
All I had to do was add the hook to my existing generator, and create
some support files to go along with it.
lib/generators/rspec/classyenumgenerator.rb
class ClassyEnumGenerator < Rails::Generators::NamedBase
desc "Generate a ClassyEnum definition in app/enums/"
argument :name, :type => :string, :required => true, :banner => 'EnumName'
argument :values, :type => :array, :default => [], :banner => 'value1 value2 value3 etc...'
source_root File.expand_path("../templates", __FILE__)
def copy_files # :nodoc:
empty_directory 'app/enums'
template "enum.rb", "app/enums/#{file_name}.rb"
end
hook_for :test_framework # <======= Add the hook here
end
More information about this hook can be found in the
"Customizing Your Workflow"
section of the Rails Guide.
After adding just the hook, I knew it wasn't going to work, but because I like
taking baby steps when coding, I rebuilt and
installed the gem, updated my project's ClassyEnum dependency,
and ran the generator anyway:
rails g classy_enum Priority low medium high
create app/enums
create app/enums/priority.rb
error rspec [not found]
This error is just saying that the test_framework generator could
not be found, which was expected because I had not created it yet.
Since I don't have any tests for the generator itself, I used this message
as a failing test, and my passing test would be when the enum spec was generated.
According to the Rails Guide, the hook_for method will search in a
few places for the generator, looking for one of a few different
class names. By default it looks for a class named after the generator that
invoked the hook, namespaced with the test framework's class name and "Generators".
In my case this would be Rspec::Generators::ClassyEnumGenerator.
I could have alternatively used the :as => option to specify
a different class name, but I wanted to use the default.
I needed the behavior of the enum spec generator to basically mimic that
of my enum class generator, the only difference being the spec location
and which template was used. My final Rspec generator class is shown
here:
lib/generators/rspec/classyenumgenerator.rb
module Rspec
module Generators
class ClassyEnumGenerator < Rails::Generators::NamedBase
desc "Generate a ClassyEnum spec in spec/enums/"
argument :name, :type => :string, :required => true, :banner => 'EnumName'
argument :values, :type => :array, :default => [], :banner => 'value1 value2 value3 etc...'
source_root File.expand_path("../templates", __FILE__)
def copy_files # :nodoc:
empty_directory 'spec/enums'
template "enum_spec.rb", "spec/enums/#{file_name}_spec.rb"
end
end
end
end
And the spec template file:
lib/generators/rspec/templates/enum_spec.rb
require 'spec_helper'
<% values.each do |arg| %>
describe <%= "#{class_name}::#{arg.camelize}" %> do
pending "add some examples to (or delete) #{__FILE__}"
end
<%- end -%>
After adding these two files to ClassyEnum, I reinstalled and
reran the generator in my project and everything worked!
Here is my "passing" test:
rails g classy_enum Priority low medium high
create app/enums
create app/enums/priority.rb
invoke rspec
create spec/enums
create spec/enums/priority_spec.rb
Which generates the following spec file:
spec/enums/priority_spec.rb
require 'spec_helper'
describe Priority::Low do
pending "add some examples to (or delete) #{__FILE__}"
end
describe Priority::Medium do
pending "add some examples to (or delete) #{__FILE__}"
end
describe Priority::High do
pending "add some examples to (or delete) #{__FILE__}"
end
Since I am using the hook_for method, it includes some other behavior,
such as supporting the --skip-test-framework flag out of the box. This
would allow someone to generate the enum classes without any specs, but
I don't recommend doing that. :)
Wrapping Up
I'm happy with ClassyEnum generator once again. It creates spec files by
default which makes me feel like I'm able to practice what I preach. I
was able to achieve all four of my goals without any crazy hacks or making
any sacrifices. I was also able to easily add support for TestUnit by
adding an additional generator and template file.
06 Apr 2013
I went to a VTTA Lunch and Learn
meeting last week focused on "Marketing Vermont as a technology state".
I've had some time to reflect on this objective and wanted to talk about some of the frustrations I've felt in
trying to address this very issue.
During the lunch session, David Parker of Dealer.com described how Vermont's
greatest opportunity to grow our economy is through the technology sector.
Vermont’s tourism revenue accounts for a small minority of its GDP, yet our
state's marketing is disproportionately focused on tourism.
In his presentation,
Parker expressed that we need to get better at educating
people in science and technology, finding startup capital, and retaining a young
energetic workforce. Instead of proposing concrete actions though, he suggests
"changing the rhetoric" by talking about what Vermont has to offer. While I
agree with his message, unfortunately talk is cheap and ideas are free, and
neither is worth shit unless you actually stand up and do something.
Unfortunately, getting the word out about these great jobs and companies is not
enough to attract people to our state. One individual at the meeting went as
far as suggesting that every ad in Vermont Life magazine should feature a
cellphone or laptop. Are you kidding me? Vermont is a beautiful place, let's
not change that. Can there not be a balance between technology and Vermont's
simple beauty without the two interfering with the other?
One topic that was missing from the lunch discussion was the role that community
plays in this endeavour. Yes, technology jobs and businesses are undeniably
important, but community is what gives people a sense of belonging. Do artists
and musicians live here because Vermont has one of the lowest unemployment rates in the country?
No, they live here because there is a community that
supports them. The role of community in the technology sector is no different.
Community is an Investment, Not an Overnight Success
Many Americans prefer band-aids to solve problems and don't consider future
repercussions of today's decisions. Why should we invest in renewable energy
when we can solve our immediate energy needs with fossil fuels? Why should we
pay higher taxes when corporations can sponsor our highways? Vermonters are
different. We don't want billboards taking away from Vermont's beauty. We would
rather pay $15 for a hamburger made from locally raised cows than $4 for a
Big Mac. More importantly though, our small communities thrive because they're not
looking for short term payoff. Community, like renewable energy, is a long
term investment and not a band-aid.
I'm organizing a software developer conference this summer called the
Burlington Ruby Conference.
Last year was our first time hosting the event and it attracted
80 developers for a weekend of networking and education in Burlington. Only about
25% of the attendees were from Vermont. The rest were from Boston, Montreal,
New York, and other parts of New England. We even had two guys from Denmark and
one from Mississippi. We also had a small number of women attend, but this year we have
been putting a lot of energy into increasing that number. We reached out to the
female developer and speaker communities, published a diversity statement and
code of conduct, and have teamed up with
Girl Develop It to offer low cost
training in conjunction with the conference. What other technology event in
Vermont can make similar claims?
This year we've reached out to numerous Vermont companies soliciting sponsorship
for the conference and have been met with the same response each time. "Sorry,
not interested. We don't do Ruby, we do _____". Fill in the blank with
Java, .Net, LOLCODE, whatever. That's great, but these companies are obviously
missing the point. When was the last time there was a Java or .Net conference of this caliber in Vermont?
This is an opportunity to support the very community that these
companies are trying to hire from. Just because a developer writes Java code
to pay the bills, doesn't necessarily mean he or she wants to do this in their
free time. If you look at the
speakers we had last year, it clearly wasn't all
about Ruby. We had talks on building location based apps, database scaling,
and multiple JavaScript talks from some of the most respected people in these fields.
Why have a Ruby conference then you ask? Simple. The Ruby community as a whole
represents the type of community that we know will thrive in Vermont. The people
are passionate, helpful, and strong advocates for diversity. Ruby developers
also tend to be at the forefront of best practices. Combined, these characteristics
lead to a vibrant, successful community. Just look at the number of other
regional Ruby conferences that have sprung
up in the last few years. Ruby may not be the
cool language anymore,
but the community is thriving. In my years of being a
Ruby developer, I've never met someone who said they only use Ruby because it
pays the bills.
This conference is going to happen whether we have local support or not. We are
fortunate to live in a city where our costs to organize the event will be covered
by ticket sales alone. We've also added a crowd-sourced fundraising effort
called "Burlington Ruby Cats"
that is not only raising money for the conference,
but also for the Humane Society of Chittenden County. Having sponsors would allow
us to do things above and beyond what a typical conference can offer such as
scholarships for students and underrepresented groups like women and minorities.
Equally as important though, having support from local sponsors shows that these
companies actually care about our community. We are not organizing this
conference to make money, infact we will be lucky if we break even given
everything we want to do. We are hosting a lakeside BBQ and providing professional
recordings of the talks free of charge. We are organizing the conference because
we want to invest in our community. We want people to think about this conference
when they think of Burlington, Vermont; thereby helping to achieve our goal of
"Marketing Vermont as a technology state".
How can I get involved?
Don't get me wrong, the Vermont software community as it stands today is awesome.
I participated in (and won)
the 2nd annual Vermont Hackathon last October. This
event was targeted toward Vermont developers and the amount of support that local
businesses gave was incredible. This was a great success for our community,
but we can't limit ourselves to a handful of these events a year, or only focus
on the business side of Vermont's technology economy.
I also help organize a number of different software related user groups in the
Burlington area. Our first group, the Burlington Web Application Group
(BTVWAG) typically has 30-50 people at any given meetup, and our latest group,
Burlington JS, filled all 35 of its slots in the first day it was announced.
These groups are run by volunteers and represent exactly what our technology
community is about.
People ask me after every meetup how they can get involved, but then I never hear
back from them. Step up folks! Acknowledging that we have a problem is the first
step, but taking action is the only way that things will change. There are a
number of community members who get this and have devoted countless hours of their free
time to building the community. Aside from the hackathon,
Vermont Code Camp, Vermont Tech Jam,
and BTVGig are other examples of events and initiatives led by
passionate Vermonters who want to see our community grow. We also have folks
like Jen Mincar at Office Squared who provide
places for these groups to gather, free of charge.
Vermont has jobs and an incredible opportunity for growth through technology,
so now is the time to start investing in our community, and investing in our
future. Please reach out if you want to
join us in building a strong foundation for Vermont's technology future.
10 Mar 2013
# Rails 4 now lets you simplify "belongs_to" association queries:
# Before
Post.where(author_id: @author)
Image.where(imageable_id: @cat, imageable_type: 'Cat')
# After
Post.where(author: @author)
Image.where(imageable: @cat)
About six months ago I added a new feature to Active Record
that allows you to write simpler queries across associated models. Compared to many of
the other new features in Rails 4,
this isn't a significant change, however I think it's pretty
handy so I wanted to talk about it and show some examples. Other than a
few small bug fixes,
this was my first real contribution to Rails, and the experience was enlightening
(saving that for another post).
It's All About the Interface
Prior to this change, any queries that used a foreign key column were required
to specify the actual column name as the hash key in the query. The biggest
problem I had with this approach is that it wasn't consistent with other
Active Record APIs. When I'm working with models, I tend to be thinking in
terms of relationships and objects as opposed to database columns.
Take the following example from Rails 3.x where you can build new
objects using the belongs_to relationship, but you cannot query with this
relationship. When you are querying, you need to shift into an object + database
hybrid mindset:
class Post < ActiveRecord::Base
belongs_to :author
end
# Creating related objects using the model association:
Post.new(author: Author.first)
# Does NOT work in Rails 3.x
Post.where(author: Author.first) # => NOPE!
# Must specify foreign key to make query work in Rails 3.x
Post.where(author_id: Author.first) # => Yup!
In the above example, I am specifying the foreign key on one side, and the object on the other.
I think it can be hard to remember when you can use the associations and when
you can't. Obviously a more practical approach would be to use Author.first.posts,
but this gives flexibility in cases where you might not have both sides of the
relationship fully setup.
The above example may seem trivial so here's an example using a
non-conventional relationship:
class Post < ActiveRecord::Base
belongs_to :writer, class_name: 'Author', foreign_key: 'author_id'
end
# Ah crap... I forgot what my foreign key was called!
Post.where(writer_id: Author.first) # => NOPE!
# Must still specify foreign key column here
Post.where(author_id: Author.first) # => Yup!
This issue becomes even more apparent when working with polymorphic relationships:
class Cat < ActiveRecord::Base
has_many :images, as: :imageable, dependent: :destroy
end
class Image < ActiveRecord::Base
belongs_to :imageable, polymorphic: true
end
Image.where(imageable_id: Cat.first, imageable_type: 'Cat')
Striving for Consistency
After seeing a few different
issues get opened, I realized
I wasn't the only one who felt this inconsistency was unintuitive. It was
causing enough confusion that people were reporting it as a bug,
convinced that it "used to work". This clearly wasn't a bug, and at some
point an unintuitive interface needs to be addressed.
I hadn't spend a ton of time in the Active Record internals so I decided
to dive in and see if I could change the API so it worked with the relationship
name. I knew that each Active Record model tracks its relationships with other
models using "reflections". Each reflection stores various properies such as the
relationship name and macro (ie belongsto, hasmany, etc).
1.9.3-p327 :007 > Author.reflections
=> {:posts=>#<ActiveRecord::Reflection::AssociationReflection:0x007f8cf391dc28 @macro=:has_many, @name=:posts, @options={:extend=>[]}, @active_record=Author(id: integer, name: string, created_at: datetime, updated_at: datetime), @plural_name="posts", @collection=true>}
1.9.3-p327 :008 > Post.reflections
=> {:author=>#<ActiveRecord::Reflection::AssociationReflection:0x007f8cf4c1afb0 @macro=:belongs_to, @name=:author, @options={}, @active_record=Post(id: integer, body: text, author_id: integer, created_at: datetime, updated_at: datetime), @plural_name="authors", @collection=false>}
As I dove further into the Active Record internals, I found the
ActiveRecord::PredicateBuilder
which is used for building the "WHERE" clause of every Active Record
query. It was not the most straightforward class I've worked with, but
the integration tests were good so I could do some exploratory testing
and know when I had broken something. After a few days of discussing
with the Rails core team about what behavior should be implemented, I
had some working code.
Conclusion
In the end, the changes I made to the predicate builder allow you to query across a
belong_to relationship without specifying the foreign key. Does it
enable you to do something you couldn't do before? Not really, however, bringing
more consistency to the API was my main goal.
Now that Rails 4 beta has been released
I encourage people to download it today and try out some simple examples:
Post.where(author: @author)
Image.where(imageable: @cat) # => Polymorphic!
I also recommend checking out the Active Record tests
for some more complex examples of how it can be used with polymorphic
relationships and single-table inheritance.
10 Nov 2012
I picked up a Kindle Paperwhite a few weeks ago to replace the one I “borrowed” from my wife. It has turned out to be a fantastic piece of hardware, and I agree with pretty much everything John Gruber has said about it. I’ve never considered myself much of a reader, but I’ve made it through some great (and not so great) books over the last couple months, and wanted to share a my thoughts on them.
I’m Currently Reading:
If this book was actually finished, I would be done with it. It is currently in alpha and only about 80 pages, but the content so far is outstanding. What I enjoy about Avdi Grimm’s writing is that he can take subjects like exception handling and objects and describe them in a way you wouldn’t think possible. After taking some time off from writing Confident Ruby to focus on his RubyTapas screencast series, Avdi finally sent out another update this morning. It’s a great book for anyone who has been working with Ruby for a while and feels like they’ve mastered the basics.

We’ve all been shit on by managers and coworkers at one point or another. Chad Fowler has been through it all too, but instead of just complaining, he wrote a book about what he learned. According to my Kindle, I’m only about 55% done, but I’m really enjoying it so far. The short, targeted chapters make it easy to pick up and read when you only have a couple minutes to spare. I would recommend this book for anyone who thinks they know everything and that managers are always wrong.
Recent readings:
If you’ve been a developer for a while but never really taken the time to properly learn JavaScript, start with this book. It will give you a new appreciation for the language and leave you longing for more. The funny thing about this book is that it’s only 176 pages (compared to the Definitive Guide’s 1,100), and a large portion is spent discussing the parts of JavaScript you should avoid or be cautious of. Since reading it, I’ve been watching some of Pluralsight’s JavaScript courses and I feel like it gave me a solid foundation for learning more.

Not only is this one of the best Ruby books I’ve ever read, it’s also one of the best programming books period. Sandi Metz is a master of analogies, and the way she explains the principals of object oriented design has me convinced I could learn anything from her. I committed to giving a presentation on Object Oriented Programming in Ruby back in September and had been working on it for a few solid weeks. This book came out about a week before my presentation, I read it in three days, and decided to completely scrap my presentation and start over. This book is perfect for Ruby developers who want to learn more about object oriented design, but do it in a language that is familiar to them.

I picked this one up after receiving a fantastic reply to a question I posted on Stack Overflow regarding Rails SOA resources. While slightly outdated by the time I read it, it has actually aged fairly well compared to other technology-specific software books. The book provides a thorough overview for people who’ve never built or consumed web services in Ruby, and a great refresher for experienced developers who have. For anyone who has read it, I’d recommend listening to a recent Ruby Rogues podcast featuring author Paul Dix. They discuss some of the changes in technology and practices since its release, and Paul reflects on how we would write it today if given the opportunity.

This book was a big departure from other tech books I’ve read in that it was written specifically for managers and not software developers. I feel like I was getting management “insider information” while reading it, and definitely have a new appreciation for the work done by non-coders. Written from the perspective of a former product leader at Google and Amazon, it was perhaps too “enterprisey” for some folks, but as someone who has worked in startups my whole career, it was fascinating to read how large companies build and ship products. Other than a couple sections I skipped such as “Understand How to Communicate with Designers”, this was a very enjoyable read.

Another departure from the coding genre, Confessions offers a glimpse into the life of a professional public speaker. I was certainly not expecting to become a better public speaker from simply reading this book, but was interested in hearing about someone else’s experiences on the subject. I’d recommend it for anyone who has done any amount of public speaking regardless of whether you want to do more or absolutely hated the experience. Communication, whether it’s public speaking or otherwise, is an important skill that very few software developers take time to learn.

I did not enjoy this book at all, infact, I didn’t even finish reading it. It is pretty much the exact opposite of Practical Object Oriented Design in terms of readability. It is too lengthy and far too comprehensive for my taste. Unless you’re planning on creating the next Cucumber or you're writing your thesis on DSLs, save yourself some time and read something else. The only reason I picked it up was because I was interested in building internal DSLs in Ruby and InformIT had it on sale for for $9.99. I might revisit it someday, but I have a fairly long list of books I want to get through, so that’s not likely to happen any time soon.
On my reading list (in no particular order):
Unfortunately I buy books faster than I read them so here’s a list of those on my immediate reading list (ie they’re already on my Kindle):
- The Art of Community: Building the New Age of Participation
- Being Geek: The Software Developer’s Career Handbook
- Team Geek: A Software Developer’s Guide to Working Well With Others
- The dRuby Book: Distributed and Parallel Computing with Ruby
- Distributed Programming with Ruby
- The Connected Company
- Maintainable JavaScript
21 Oct 2012
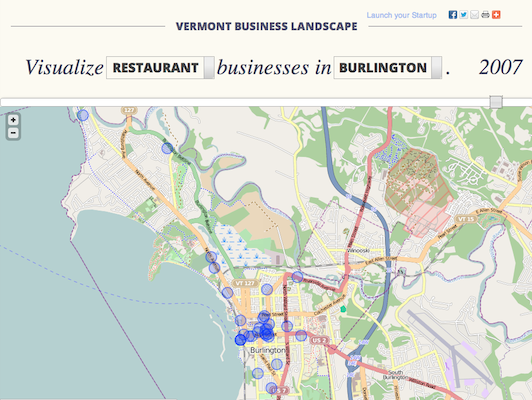
This post describes how our team, Datamorphosis, won the HackVT hackathon, and the strategy we used to ensure that if we didn’t win, we’d at least be proud of what we built. Read on to find out how we formed our team, brainstormed an idea, researched and planned our application, executed during the event, which technologies we used, and how we presented our winning application: The Vermont Business Landscape.
Forming a Team
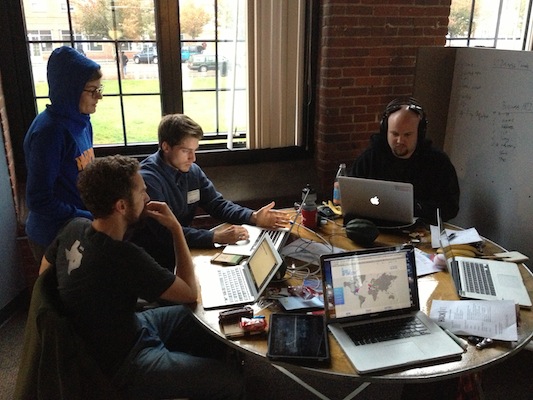
Hackathons are not just about writing code. They are about solving a problem in the most succinct way possible, and effectively communicating the problem and solution in a remarkably short period of time. Having the right team is critical to accomplishing that goal. There are very few people in this world who alone can brainstorm an idea, aggregate complex data, build APIs, design a usable interface, and present their work in front of a judging audience. The rest of us are mere mortals. Forming a solid team is about understanding the strengths and weaknesses of each member, and how they will fit together.
Our Team:
Combined, our team was highly skilled in web design and development, data analysis, user experience, and communication; precisely the skills needed to succeed in a hackathon. Almost every member of our team had previously worked with another member at some point in the past. We understood each other’s strengths and weaknesses and knew exactly how each person could contribute. This allowed us to trust one another and stay focused on the tasks that we were most qualified for.
Brainstorming and Planning
When selecting our data set, there was one theme that seemed to resonate with our team: Incorporating data that was challenging to aggregate and analyze. The reason for this is that many successful business models are built around simplifying a tedious task. Our team believes in the value of small businesses to Vermont’s economy, and in doing research, we discovered that the state has a need for aggregating business data from disparate data sources. The Community & Economic Development Office receives frequent inquiries from prospective new business owners as to the health of various sectors throughout Vermont.
Once we had a vague idea that we wanted to build a tool to assist new business owners, we began to research and plan our application. Our team met a few times during the week leading up to the hackathon, and used Flowdock to discuss ideas (even when we were in the same room).
Here are a few of the areas that we researched:
- Market need - If you’re trying to solve a problem for someone other than yourself, find a real person who has this problem. Talk to them and see how passionate they are about it. In our case, the person we spoke with at the Community & Economic Development Office was ecstatic about our proposed solution. This validated our idea and gave us confidence going into to the competition.
- Judges - Information about each judge was available on the HackVT website. We discussed as a team what sort of things they might be looking for, and planned to account for this in our application. For example, Justin Cutroni works on the Google Analytics team, and we assumed that analyzing and simplifying complex data was something he is passionate about.
- Technology - Spending time up front discussing and researching technologies is well worth the effort. After choosing an idea, we made a list of all the potential tools we might need to build it. Members of our team had overlapping skill sets so we were able to make some important decisions before the competition began.
- How to win a hackathon - We even spent some time researching how other people won hackathons.
Execution
Given the amount of upfront work we did, we were able to start the hackathon with confidence and direction. We knew who was doing what, and essentially hit the ground running. We made a couple mistakes along the way and had to pivot a few times, but overall we were able to stay focused on our goal and finish within the allotted time.
What we learned:
- Start early - Though the hackathon didn’t officially kick off until 6PM, they allowed teams to set up and start coding at 3pm. These early hours in the competition are critical. Everyone is awake and can make reasonable decisions, and being there early makes things a little less stressful.
- Avoid perfection - This is a hackathon, and it’s ok to write hacky code. People who know me or have seen some of my presentations know that I’m a stickler for good code. Building a production application for your customers is one thing, but hacking something in 24 hours for a three minute presentation is another. Put aside your pride and just get it done.
- Focus on the core - Since you will likely run into unexpected hiccups along the way, focus on building the core first and iterate on it. Will your application still function and be presentable without feature X? If so, it’s a low priority. In our case, showing data on a time-lapse map was the core of our application. Without this, it would not have met our goals. We tracked a list of our priorities on a whiteboard and delegated each task in order of importance. By focusing on these must-have features, we were able to have a simple application that was easy to finish and demonstrate.
- Don’t panic - When we are tired and under stress, we tend to make bad decisions. Our team encountered a serious bug in the final hour and realized we didn’t have time to fix it, so we prepared our presentation accordingly. We spent our last 30 minutes planning a path to walk through the application that we knew we could demonstrate with confidence.
- Know when to cut a feature - This goes along with focusing on core functionality. Some features will take up too much of your time and don’t add enough value. If it doesn’t feel right, cut your losses and move on. We had a few awesome features that we decided to axe at the last minute. If you’ve prioritized your todo list, the tasks ranked as “nice to have” will likely get pulled.
- Design for presentation - Chances are, your application is going to look 100x worse on a large, lower contrast projector screen during the presentation. We planned for this by using large, readable fonts and designing simple interface. If the judges can’t make out what it is, it will just be visually distracting.
- Asynchronous communication - Even when we were sitting at the same table during the event, we continued using Flowdock to communicate. We found this asynchronous form of communication to be vital to our productivity, allowing people to propose ideas, share links, and notify others about code changes, without breaking from their workflow.
- Don’t bother with user authentication - No one cares that you added a 3rd party authentication system to your app. If your application isn’t secure for the presentation, this is actually a good thing because you won’t be wasting valuable time trying to remember your password.
Presentation
In planning for the event, we anticipated having at least five minutes to present our idea. It turned out we only had three. Three minutes is not a lot of time for anything, let alone present a problem, solution and walk through a software demo. Every second is valuable and should be spent selling your idea to the judges.
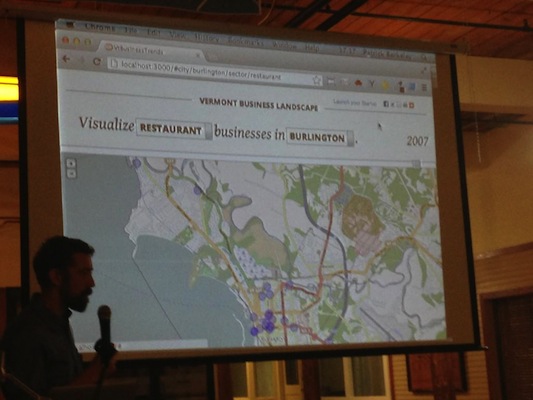
Here are some tips for nailing the presentation:
- Get some rest - With a five person team, we had the luxury of making sure the people representing our team were well rested. Only two of my teammates actually coded through the night. It’s easy to make stupid mistakes when you’re tired, and you don’t want to blow all your hard work in the last 3 minutes.
- Practice your pitch - Our presenters spent hours preparing for the demo. They practiced what they were going to say and how everything was going to flow. This extra effort definitely paid off in the end.
- Don’t talk about the technology - You’re here to brag about your application, not about the tools you used. If people are interested in what you built it in, they will ask.
- No one built a perfect application - I’m sure everyone’s application had at least one embarrassing bug. Ours had at least three that we were aware of. Don’t apologize and bring attention to these faults, the judges probably won’t even notice. We planned our demo to avoid these issues, and no one besides us knew they existed.
- Focus on your product - Don’t rely on presentation slides to help sell your app. Though most of the judges looked well rested, everyone else is tired and just wants to see your application in action.
- Just because you built it, doesn’t mean you have to show it - There were quite a few features we developed that did not even get mentioned during our demo. They would have been great to show off if we had a few more minutes, but they were not polished and did not really add core value.
Technologies Used
Final Thoughts
Winning the hackathon means so much more to our team than the cash or prizes. HackVT was by far the most well organized Vermont event I have ever attended. Every last detail, from the quality of food to the mounted, decorative data sets, made the developers feel welcome and comfortable during our 24 hour stay. This event demonstrated the level of commitment that companies like MyWebGrocer and Dealer.com have made to Vermont, ensuring our state becomes a sustainable technology hub and attract talented individuals for years to come. Thank you to all the volunteers, sponsors, and participants who made it happen. See you again in 2013!
